![]() Cinema Journal Teaching Dossier
Cinema Journal Teaching Dossier
DH and Media Studies Crossovers Vol. 3(3)
Kevin L. Ferguson
Queens College, City University of New York
I see this question on Twitter: “Someone shouting, ‘We got company!’ is a classic action movie cliché. Does anyone know the earliest film to use that line?” My immediate thought: a perfect question for a digital humanities approach to cinema and media studies! My students would know how to answer this, and they would also know how the question needs clarification.
I often see semi-serious questions about film history like this on Twitter: what are the anti-feminist semiotics of pizza versus Chinese takeout as it coded female protagonists in 1980s popular films? What television show was the first to begin with the now-formulaic “Previously on . . .” or “Last week on . . .”? Questions like these address themselves to a new media studies informed by digital humanities’ search-oriented promise of direct access to large datasets, one with significant pedagogical opportunities to teach students the difficult skill of refining suitable research questions. On Twitter, users answer these questions with educated guesses based on their film history knowledge, but the answers are often little more than stabs at trivia, relying on traditional forms of knowledge-making that require either accessing a store of previously-remembered information or searching reference works like IMDb or Wikipedia.
While questions about action clichés or movie pizza might seem to be idle ones, the subtleties in answering them get students to think about fundamental problems with traditional media studies’ reliance on the personal investigative mode and how a corpus-driven approach might be able not only to augment traditional methods but also do things that traditional methods cannot. For example, one person proposed Han Solo in Star Wars (dir. George Lucas, 1977) as an example of the line “we got company,” while acknowledging it was unlikely that this was the first appearance. This guess relies on personal memory and intuition, which we want to encourage in students, while at the same time recognizing the limits of even a lifetime of watching films. While Han Solo’s might arguably be the most memorable or significant or ironic use of the cliché, this claim is of a different order than an answer to the objective historical question posed. Thus, we might still teach students to answer traditional questions like “how has the action genre been defined historically?,” but we can now better address those questions with digital methods that answer specific research questions like “how has the color palette of action movie posters evolved over time?,” “with what frequency have industry publications used the word ‘action’ to categorize types of films?,” or “do action film screenplays have a notably different structure than other genres?” In this way, students can get a richer sense of the kind of film historiography described by Robert Sklar, who argues that “the practice of historiography is fundamentally dialogic. Historical discourse is constantly being transformed through historians’ commentaries and critiques on the work of other past and present historians.”[1] Thus, students can see how film histories are written and rewritten by new digital methods and techniques.
Subtitles
One way students in my digital humanities courses are taught to pose and answer such media history questions is by treating film and television subtitles as a textual archive for research. Using free tools such as the command line and Voyant, students manipulate a large, readily available corpus of film and television subtitles from OpenSubtitles.org (they claim as of September 2015 to have 3,441,809 subtitles). Media texts are subtitled for a variety of reasons: closed-captioning for hearing-impaired spectators, translations of foreign or accented speech, and for use in public places where audio is muted or hard to hear. While celluloid, VHS, and early DVD releases may have included subtitles that were irreversibly “burned” onto the moving image itself, contemporary practice for digital television and video distribution is to include subtitles within the image track which can be turned on or off by viewers. A third possibility, increasingly common online, are “softsubs,” which are a separate text, XML, or HTML file with subtitles specially marked with a timecode so as to align with specific digital releases or rips of film and television shows. Softsub file formats like .srt, .sub, or .usf are popular since viewing them is as simple as dropping them into the same folder as the video file. Unlike the encoded graphics subtitles on commercial DVD or Blu-Ray releases, which require special software to remove, softsubs can all be quickly converted to plain text and thus machine read in ways that are already familiar to digital humanists. In fact, the .srt files commonly found on OpenSubtitles.org are already plain text and so require very little work to manage. Here is a sample of the .srt file produced by the program SubRip, which uses optical character recognition (OCR) to process on-screen graphics subtitles from a DVD. Note the subtitle number, timecode in hour:minute:second,millisecond format, and the displayed text from the classic 80s horror film A Nightmare on Elm Street.
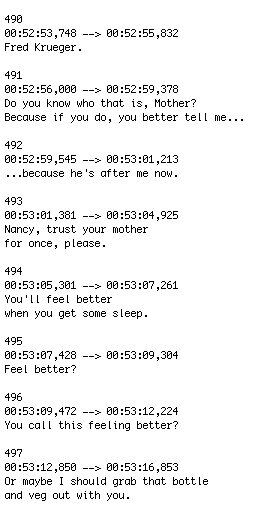
Figure 1
The separation of the subtitle from the image track creates a new paratext for media scholars to investigate digitally. As with any paratext, we should not confuse these with the actual film or television soundtrack. Some differences for students to keep in mind when working with subtitles: we are not looking at a script or screenplay with actor’s names, locations, or stage directions; we are not looking at a transcription that includes sound effects (as with closed-captioning); we have no sense of nuance (dialogue spoken ironically or contextualized with hand or facial gestures); and there is no soundtrack to signal emotional content. Furthermore, subtitles are restricted by conventions that fit their purpose: they must abbreviate spoken dialogue to fit on screen (using two lines of about 40 characters each), they must indicate when it is unclear who is speaking, they use ellipses to show when a character’s speech lasts more than two lines, and they must indicate off-screen speech. But even with these limitations, subtitles offer a “good enough,” readily available solution to a large set of otherwise unanswerable research questions.
Method
There are some simple web interfaces for searching subtitles: IMDb allows for searching a limited database of movie quotations, Subzin offers a larger database, and even appending “srt” to a Google search returns a set of useful results. But because of their relatively small selection and user-generated nature, these sites mainly confirm for students how important it is to consider the source, quality, and limitations of their corpus. The next step is to ask students to identify and prepare their own corpus using OpenSubtitles.org, for example the subtitles of 2–3 seasons of a television show; the films of a particular director or writer; or a representative set of genre, historical, or national films. Here are three such sample subtitle corpora: twenty-five episodes of the first season of the television show The Golden Girls, a dozen films written by Nora Ephron, and a dozen horror films produced between 1980 and 1989.
Following advice on a handout like this one, students download the appropriate subtitle files, use the command line to clean out the timecodes and rename the files, and create a compressed folder of their corpus for later analysis. For beginning text analysis, I ask students to use the program Voyant,[2] a set of textual analysis tools which can either be accessed via the internet or through a browser-based server downloaded for offline use. I point students to Voyant’s own excellent tutorial workshop documentation. As an example, loading season 1 of The Golden Girls into Voyant’s default skin reveals a number of windows showing information about word count, word frequencies, which words and texts (in this case, episodes) are most unique and which most common, and sparklines showing the trends of individual words over time (in this case, over the season).
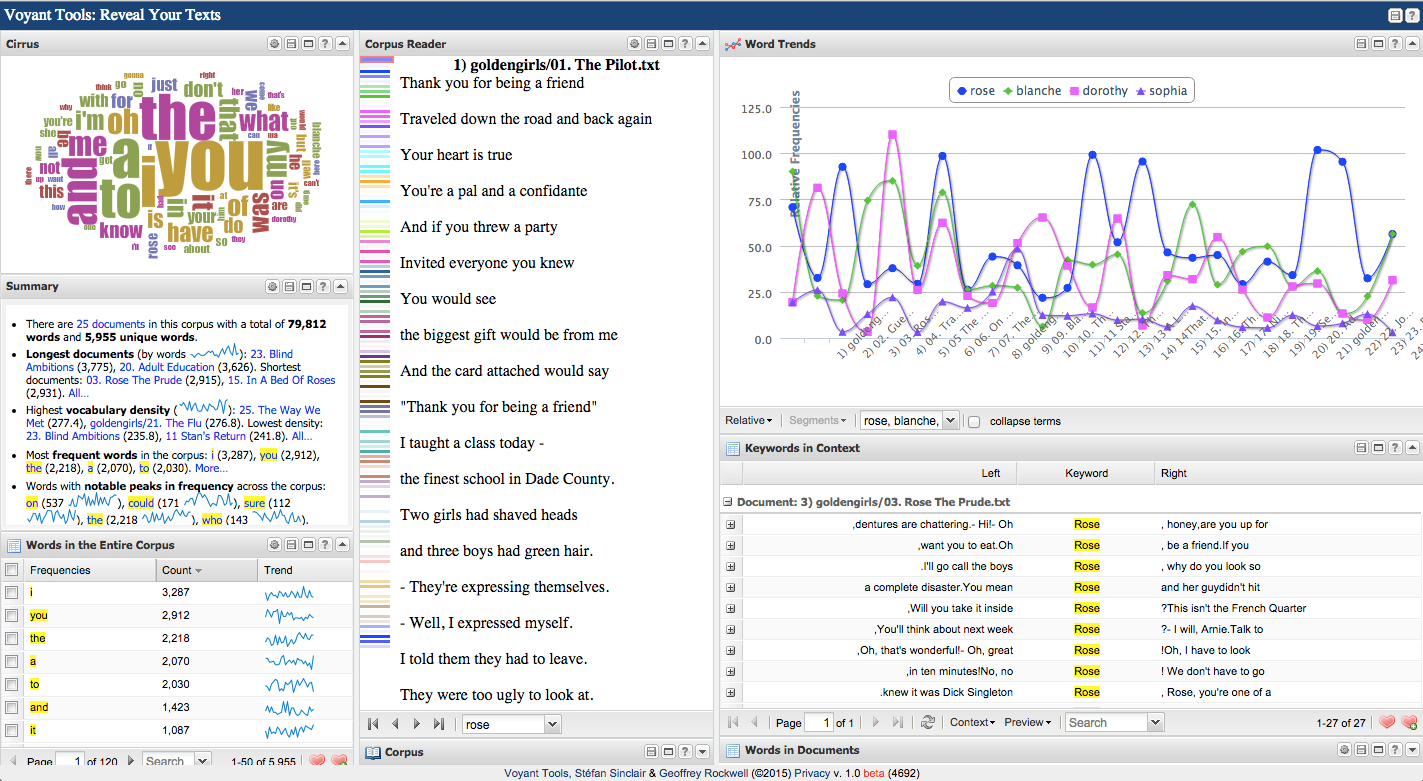
Figure 2
Users can click on any word to see it revealed in each tool or can search for specific words. For example, we might wonder if the four central characters Rose, Blanche, Dorothy, and Sophia tended to be named equally in the show or if some characters were mentioned more than others in individual episodes or over the course of the season. The “Word Trends” sparkline in the upper right shows us at a glance that while Sophia is consistently but rarely mentioned, the other three tend to dominate individual episodes, with exceptions like episode 8 where all four are relatively unmentioned. We might next use the Bubblelines tool to see what these trends look like in individual episodes, noting for instance how the overlap of names marks moments of conversation, interpersonal conflict, or off-screen speech, as in conflict-heavy episode 5 “The Triangle.”
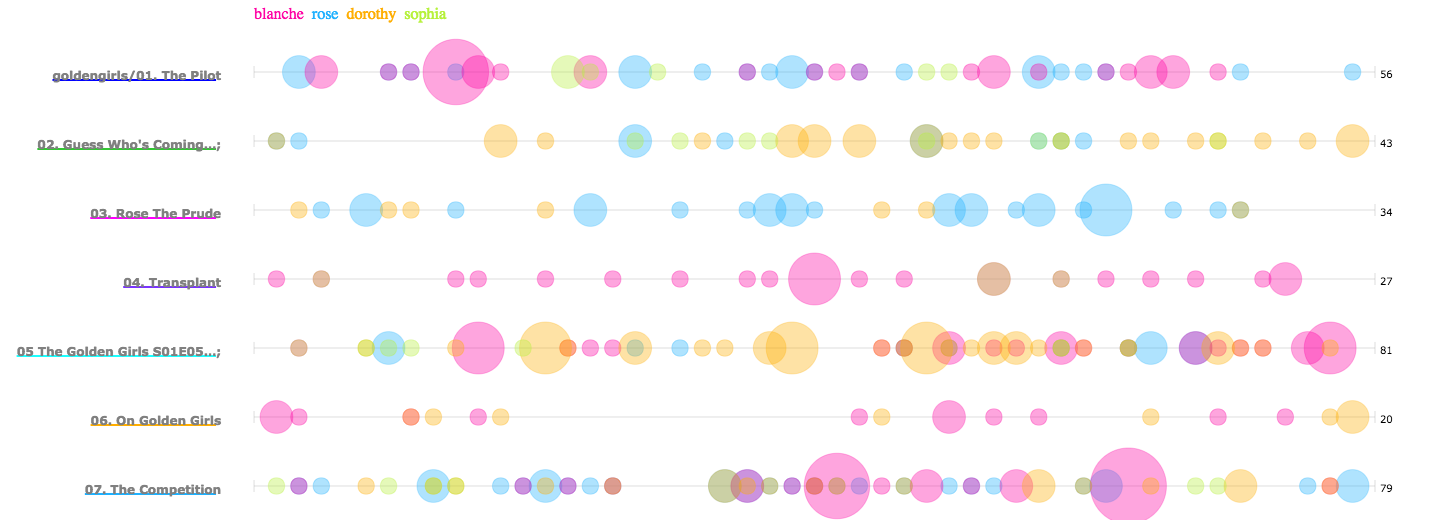
Figure 3
Voyant works well to allow students to visually wrangle the otherwise invisible dialogue from media texts. However, for broader questions about media history, like the ones I began with, we need a much larger corpus. For this, students can work directly with the English-language subtitle corpus files from here: about 310,000 gzipped XML files in a 6.5GB folder.[3] This can be unwieldy to work with, but since the corpus is organized in subfolders by year, portions of it can be assigned. Students might use the command line to search for phrases or words, i.e.:
find . -iname ‘*.gz’ -exec zgrep “got company” {} +
which returns results that look something like:

Figure 4
Ignoring the duplicate entries caused by multiple subtitles of different video releases, we see results for our search phrase in chronological order. No doubt your local computer scientist can suggest other ways to find phrases in files using the command line.
And the answer to the “we got company” question? Maybe Jack Conway’s 1940 Boom Town, a Clark Gable–Spencer Tracy comedy, but students quickly discover that we first need to redefine what “action genre” even means before we are able to speak with any certainty. While “we got company” is a cliché of action movies today, there are numerous early examples of the phrase’s ambiguous use that force students to pay attention to the changing context of spoken dialogue. For instance, one early use of the phrase is in Applause (dir. Rouben Mamoulian, 1929):
Come on in, boys and girls, we got company.
Gee, Kitty, the baby looks great.
Oh, isn’t it cute?
It looks just like Kitty.
This is certainly not an action film and “we got company” does not have the same euphemistic overtones as in later uses, but the menace of this scene is apparent and later the film in fact parses the meaning of the word “company”:
Just looking for somebody to talk to.
Sailors don’t generally have much trouble finding company.
Oh, I don’t want the kind of company you mean.
Listen, all sailors ain’t a bunch of bums.
Finding an answer to what seems like a straightforward question instead requires us to consider even more fundamental questions, like what defines the action genre, when do phrases become clichés, or why is the “first occurrence” privileged in historiography. In this way, using freely available and simple computing tools allows students to focus on the process and method of archival research: while there is an important aspect of investigative play with the tools, the emphasis is on refining a research question through experimentation.
[1] Robert Sklar, “Does Film History Need a Crisis?” Cinema Journal 44.1, 2004, 134.
[2] There is an improved beta version of Voyant 2.0 here: beta.voyant-tools.org
[3] Jörg Tiedemann, “Parallel Data, Tools and Interfaces in OPUS” in Proceedings of the 8th International Conference on Language Resources and Evaluation (LREC, 2012).